奶奶都能看懂的 C++ —— 函数返回值、作用域和生命周期
上一篇,我们讲解了函数的基本知识以及参数传递的方法和实质,我们今天来聊聊返回值以及作用域、生命周期。
函数返回值
我们上一篇的例子中,函数的返回值都是 int 类型的。实际上,你可以拿多样的类型作为返回值。我们先从最简单也最特殊的一种开始——无返回值。
void
void,英文里面是空的意思。返回值为空,也就是什么也不返回。如果你的函数只是执行一些操作,不需要把结果给到调用它的函数,那么选择这个类型是非常合理的。比如下面的函数,会直接输出一个 vector:
1 | |
当然,你也可以提前返回,此时我们直接写 return; 即可:
1 | |
完美!关于空返回值你已经完全学会了。
有返回值
刚才是没有返回值,现在我们来看看有返回值的情况。注意了,我们这里说的返回值,可以是一个对象,也可以是一个引用,但不能是一些奇怪的类型(数组或者函数本身)。
关于怎么迂回地返回数组,我们将在下方讨论。先来看看正常一点的情况,和参数一样,我们得知道——值到底是怎么返回的?
……这问题实际上一句话就能总结,和参数一模一样的传递方式,也就是将 return 后面的值,用于初始化 一个 返回到的点的 临时量。
说人话:
- 在返回到的那个地方,创建一个临时量
- 把 return 后面的内容赋值给它
不过和传递参数不同,由于这是返回值,我们还要加一个问题:返回的(那个创建的临时量)是右值(临时量),还是左值(具有确定位置的对象)?
我们分开来讨论值和引用,仔细聊聊其中的原理。
首先是非引用类型的返回值,此时函数返回值是一个临时的右值。
1 | |
奶奶都知道结果是 2,这个函数接受 a,然后返回其两倍。此时 cout 接收一个右值并输出。
注意,因为是非引用类型,也就是个具体对象,所以也包括指针。同时,const 也是适用的,这里就不啰嗦了,同样的说太多遍也没意思。
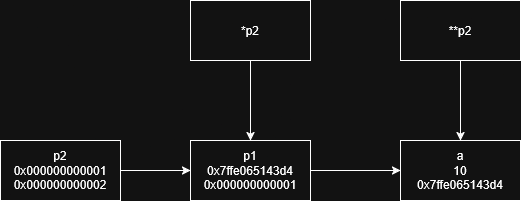
当结果是引用的时候,就不一样了。当你返回一个引用,那么就说明你的对象具有确定的内存位置(我们之前提到过,引用就像贴标签,本身并不是对象,只是给其它对象起了个别名),因此,此时返回的是左值。也就是说,你可以给返回值赋值:
1 | |
虽然上面的代码看起来像大脑发育不完全写出来的东西,不过它确实很好演示了返回值是左值的状况。
另外,得提醒一点:不要返回函数内部创建的对象(称为局部对象)的引用或指针。这是因为,函数调用完成后,内部的对象会被释放。这会导致引用或指针失效。具体的详细解释在下面。
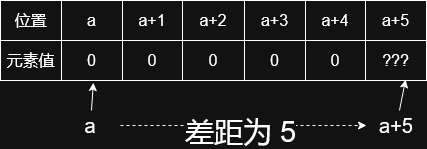
返回数组
在 C++ 中,无法将数组作为返回值(数组没办法直接赋值给临时量),所以我们得选个其它方法返回。
在上一节中,我们强调了退化为指向首个元素的指针和指向整个数组的指针的区别。而对于返回值来说,我们显然需要的是后者——只要解引用,就能直接取得数组对象。
先来看看我们一般是怎么创建指向数组的指针的,比较一下下面的代码:
1 | |
这是因为,创建变量时,[] 优先级更高,从变量开始往两侧读,优先级高的那一边,就是实际的数据类型。加上括号,就让 * 优先结合,因此结果是指针。
也就是说,第二行创建的是数组,第三行才是正确的指针。我们类比过来,当作为函数的返回值时,可以这么写:
1 | |
当然,引用也是支持的:
1 | |
作用域和生命周期
你可能已经注意到了,在函数中,有些时候变量可以用,有些则不能用或产生了意外的结果。要想搞清楚这个问题,我们必须了解两个概念:名字的作用域和对象的生命周期。
名字的作用域
我们一直在给对象起名字。但是,名字一般只在程序的一部分中具有意义。让名字具有意义的地方,就叫做作用域(起作用的地方)。
在 C++ 中,名字的作用域,一般是一对花括号,也就是块(或者整个程序)。一旦在作用域中声明(不是定义)一个名字,那么它就在该声明语句到作用域末尾有效。
我之所以强调名字,是因为这个声明可以是变量,也可以是函数,或者任何有名字的东西。C++ 都是通过名字来查找对应内容的。
这么说起来有点抽象,来看具体例子。我们把上次讲声明和定义的例子改一改:
1 | |
刚才提到,整个程序首先是一个作用域,这叫做全局作用域。观察没有包裹在花括号中的声明,可见 addAB 和 main 都属于全局作用域。
这也就解释了我们上一节的内容:只要头文件里面声明,源代码中定义,那么就属于全局作用域,一旦 #include 头文件,就能直接使用。
而再看块中的内容。首先是 c,它在一个块中,这叫做块作用域。我们说过,名字的有效区从声明到作用域末尾,因此,c 仅限在 main 定义之后的区域中使用。
我们之前早已遇到过块的嵌套,比如 while 和 for 循环。它们也是一个块,因此也是独立的块作用域,所以在其中声明的名字无法在作用域外被找到。
但有个比较棘手的问题就是,如果内层作用域声明了与外层作用域相同的名字,会发生什么?(是的,C++ 允许你这么做)
我们很容易得出,外部作用域内、内部作用域外的地方,只可能查找到外部作用域的名字。
但内部作用域内呢?比如下面的代码:
1 | |
我们刚才说了,名字的有效区域是它的声明到作用域末尾。外部的全局作用域中的 a 有效区域是第一行到末尾,内部的 a 有效区域是第三行到第五行的花括号。因此,第四行两个 a 都有效。
很简单:内层隐藏外层。查找对应名字优先查找内层有效区域,再查找外层有效区域。
但有一点需要注意,不能在同一个定义域内,声明一个名字两次:
1 | |
对象的生命周期
刚才讲解的是名字本身,我们现在来看看名字对应的对象(既然是对象,那么不包含函数。只有对象有生命周期)。
对于一个有名字的对象,我们将创建对象的过程,叫做定义。有创建,就有销毁——对象存活的全过程,叫做对象的生命周期。
当我们在函数体外部(类似于全局作用域区域)中定义对象时,这些对象将从程序启动开始存在,直到程序结束才被销毁。也就是说,这些对象的创建将在 main 函数前执行。
小提示:分清楚作用域和生命周期的区别。对象被创建了,不等于一定能够根据名字访问它。后者是由作用域决定的。比如,我们在 main 函数后面定义一个变量,这个对象确实在启动时创建了,但是 main 函数内部并不是名字的有效区域。因此,我们无法通过名字找到它。
1 | |
而当我们在函数体内部定义对象时,对象将在它所在的内层块的末尾被销毁。
1 | |
a 在离开 main 时销毁,b 在 if 块末尾销毁。
既然作用域已经决定了我们能用哪些名字,为什么还要强调生命周期呢?
还记得吗?返回值那里我们强调了:
不要返回函数内部创建的对象(称为局部对象)的引用或指针。
这和生命周期(而并非是和名字有关的作用域)有关系。我们知道,函数体内的对象在块结束时销毁。当你返回了,那么局部对象一定已经被销毁了,此时你的引用或指针就无效了。
静态对象
你或许早有预感:我们是不是要来点特例了?
没错,静态对象就是这样的特例,它们在函数体内定义,在变量类型前加上 static,但生命周期是从定义之后,到程序结束。比如,下面的代码会输出之前已经调用这个函数的次数:
1 | |
当然,虽然生命周期改变了,但是对应名字的有效区域还是一样的:从声明开始,到作用域末尾。
我们已经对函数有了相当程度的认知,了解了返回值和作用域,以及对象生命周期。下一篇,我们将看看什么是函数重载,它让我们能够轻松编写函数。
 爱发电
爱发电 公众号赞赏
公众号赞赏