奶奶都能看懂的 C++ —— 函数与参数传递
这次让我们来聊聊函数。当你的程序越写越长,不可能把所有代码都放在 main 里面,否则找个代码翻好几页是迟早的事情。函数允许我们一次只做一件事,把不同功能分离开来,放在一个或多个文件中。
函数
写一个函数,最重要的是三点:函数体(操作),函数参数(输入),函数返回值(输出)。我们先从大家都熟悉的 main 函数入手(是的,它也是个函数):
1 | |
先看第一行:int 放在最开头,表示返回值是 int,然后紧接着的是函数名称 main,后面是一个括号表示参数(默认的 main 并没有参数,所以括号里面是空的)。
2、5 行有一堆大括号,它们就是我们所说的块。函数的函数体通常是一个块,允许我们写多个由分号分隔的语句。
然后让我们进到块里面,return 0; 这一句,表示执行至此时,立即返回 0。因为这是主函数 main,所以我们返回 0,表示的是程序已正常运行完成并退出(返回 0 表示正常,这是一个操作系统的规定,先别问为什么)。
好了,你现在对函数应该有一个基本的了解了,我们可以开始编写自己的函数,然后调用了。
编写并调用函数
1 | |
上面是一个非常简单的示例,演示了函数的基本使用方法。
我们刚才说了函数的三个重要组成部分,我们先来看看 1-3 行的函数本身:
- 我们定义了一个 int 返回值的函数,名字叫 addAB
- 函数有两个参数,都是
int类型,名字叫 a 和 b - 我们在其中执行加法操作,并返回加法的结果
现在再来看看 main 函数,我们在其中直接写了 addAB(1,2)。这句语句的意思是,先中断 main,然后向 addAB 传入 1 和 2,分别作为 a 和 b 的值,再执行函数体内的语句,等待执行后返回,将返回的值,作为结果。
因此,输出是 3。
声明和定义
你或许注意到了,在上面的代码中,我们把 main 放在了 addAB 的下方。这个顺序是非常重要的,因为编译器会从头开始编译,如果你把 main 放在上面,那么会由于找不到 addAB 而报错。
现在,我们稍微改一改代码:
1 | |
你先自己试试,然后猜一下:为什么这么写也可以通过编译?
这就要提到声明和定义的区别了。
先顾名思义,声明,告诉你我在这里;定义,告诉你我具体是怎样的人。函数中也是一样:
声明,告诉编译器有叫做我这个名字的函数;定义,告诉编译器我这个函数具体做什么。
也就是说,第一行的声明,只是告诉你有这么一个函数,返回值 int,名字叫 addAB;而函数体由分号替代,把定义的权力让出来,可以在后面再写函数体。
小提示:声明的参数列表是可以省略的,但是建议你写一下(并确保和定义一致),这样可以让阅读代码的程序员更好理解函数的功能。
把声明放在上面,main 就能够找到已经声明的那个函数了。只要在任意位置定义一下,即可被找到。
或许有人会觉得没用,但是你想想,如果我把所有的函数声明写在一个头文件里面(对应的定义需要 #include 这个头文件),那么,只要在 main 前面引用这个头文件,就可以随意使用那些相关的函数,而不用去一个个引用源代码文件了。
函数的参数传递
现在我们来仔细聊聊参数问题。
我们刚才一直在说,把参数传入,但这到底是怎么传递的呢?要解决这个问题,我们得先了解形参和实参的概念。
形参和实参
什么是形参、实参?形参,即形式上的参数;而实参,则是实际的、真正的参数。
在我们刚才的代码中:
1 | |
1,2 两个数,是实参,而 a,b 则是形参。当调用这个函数时,对应的实参将会用于初始化对应的形参。在这时,无形化为有形,形参变量有了新的值(在这个例子中,是 1 2)。
也就是说,有以下等价代码:
1 | |
引用传递和值传递
那么问题来了,如果参数不是普通的类型,而是引用和指针呢?
其实我们根本不用过于纠结。这是因为,我们可以直接写出等价的初始化语句,来判断到底是如何传递的,来看看下面的例子:
1 | |
当传入引用时,相当于有这样的等价初始化:
1 | |
也就是说,a b 是 c d 的别名(引用),改了 a b 相当于改了 c d。
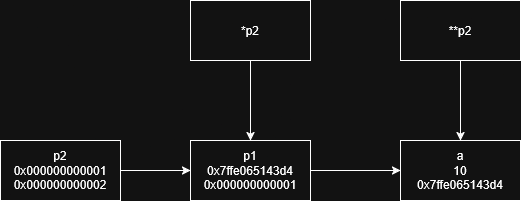
我们把这种传递引用的过程,叫做引用传递。而不传递引用,传递值的过程,叫做值传递。现在你可以想一想,如果传递一个指针,属于哪一种呢?
想都不用想,肯定是值传递啊。指针也是一个对象,存储了一个对象的地址。因此,相当于传递了地址这个值。
1 | |
如果你还是不理解,不妨也写出等价初始化:
1 | |
const 类型
我们在const 限定符与指针一节中,已经探讨了存在顶层和底层 const 时候,初始化指针和变量的规则。根据上面的讨论,你可以直接写出存在 const 时候的等价初始化,并利用规则,此处不再赘述。
小提示:当函数内部不应该改变形参的值,建议把参数定义为 const 类型。这样,无论传入的是否为常量,都可以防止意外修改。这在参数为引用时非常需要注意,下方解释了原因。
我唯一要强调的一点,是常量引用的初始化。你应该还记得,我们说过,当初始化常量引用的时候,初始化值可以不是变量,而可以是字面量(右值),允许违反引用的特性。
这一点会为函数产生很多好处:有时候,我们只是需要在代码里面控制一些参数的值,没必要使用变量;而有时候,我们想要避免多次拷贝值,还要避免意外的修改。
因此,常量引用为我们提供了一个完美的解决方案——
1 | |
用变量?用常量?用临时量?全都没问题,还能节省拷贝开销,同时防止不小心修改。
小提示:等价初始化是任何时候都有效的。如果你没明白,自己写一下上面的三条调用语句的等价初始化,相信你很快就会明白了。
数组传递
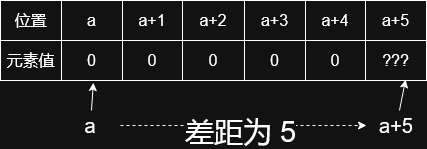
我们已经提到过,数组特定情况下会自动退化为指针。也就是说,如果参数是一个数组,传入的实际是指针。
要补充强调的事情是,退化为指针意味着丢失了除了在内存中位置以外的信息。也就是说,我们如果把数组作为参数传递(它变成了指向首个元素的指针,已经不再是数组了),是没法知道它的长度的,也不能用 begin() 和 end()。
小提示:搞清楚指向第一个元素的指针和指向数组的指针。前者是退化而来的,你没法再获取数组的信息;后者可以直接解引用获得数组这个对象本身,得到的解引用对象也就包含了它原来的所有属性。
正因如此,形参中数组的长度并不重要,可以省略不写:
1 | |
提示:如果你传入的数组长度不确定,可以加一个参数表示长度。或者直接传入首元素和尾部元素后一个位置的指针。
另外一个容易困惑的点是下标运算符,为什么退化后还可以正常使用?实际上,下标运算符只是指针运算的一种等价形式而已。
1 | |
a 是一个数组,上面两条语句是等价的!
main 函数参数
好好好,在深入了解完传参的机制之后,是时候回来看看 main 函数了。我们刚才提到它默认没有参数,但实际上,它可以加入参数,表示从命令行接受的参数。
1 | |
仔细看看上面的代码。argc 表示,传入的参数有几个,而 char *argv[] 表示 指向 传入参数的 C 风格字符串 的 首个元素 的 指针 的列表。
绕晕了都。
先说说 C 风格字符串,以前,在没有 string 标准库的时候,程序员们都用数组来存储字符串。它是一个 char 数组,数组中每个元素都是字符串的一个字符。数组长度不知道,因此规定,从数组开头元素开始向后,当遇到 ‘\0’ 这个结束符的时候,表示上一个元素就是字符串的结尾,结束符后面没东西了。
不过新编写的程序应尽量避免使用 C 风格字符串,因为 string 更安全快捷,C 风格字符串只是一种兼容性的妥协。
现在来让 main 参数说人话:
- 传入多个参数,每个都变成了 C 风格字符串,
- 取得指向每个字符串(char 数组)的首个元素的指针,
- 把这堆指针放到另外一个数组里面。
因此,上面的代码的意思是,先取得第一个和第二个参数,然后把它们转换成 string 连起来。
要注意的是,参数从 argv[1] 开始。argv[0] 是程序的名字。同时,我们不能指望指针指向的字符串能被修改、延长,因为它们是 C 风格字符串。
可变参数长度的初始化列表
C++ 中还有一个很有意思的东西叫做 initializer_list<T>,允许我们传入不定长的参数,这些参数是同一个类型(写死在 <T> 中),但是数量不定。
看看下面的代码:
1 | |
这段代码对整个参数列表求和。initializer_list 有 begin() 和 end(),允许我们获取指向首个参数和尾部参数下一个位置的迭代器。而传入参数时,传入的是一个列表,所以需要用大括号包裹。
好了,我们已经涉及了相当多的、深入的函数知识了,下一篇,我们将继续探索函数,了解函数的返回值,以及重载究竟是什么,依旧是最简单生动易懂的语言。
 爱发电
爱发电 公众号赞赏
公众号赞赏